
基于多年研发的CVKit™ NN IP的N1系列SoC芯片刷新了端侧AI芯片性能记录。领先的每TOPs处理帧数,实时数据流处理能力,支持高精度FP16神经网络模型直接无损部署,高性能的INT8网络支持能力,多级精细功耗控制,将端侧AI芯片的能力提升到了一个新的高度。
01.单位算力下,谁能够支撑更快更准的神经网络推理,是衡量AI芯片性能的关键
对于AI应用和系统厂商而言,AI芯片是其核心元器件,是人工智能的基础设施,其重要性不言而喻。 每个应用和系统厂商都在寻找在性能、功耗、成本等方面综合因素下合用的AI芯片。 评估AI芯片是否适合使用往往从每元钱能获得的性能、每度电能获得的性能、部署实施的成本、元器件是否稳定可靠等几个方面来衡量。其中,芯片厂商宣称的每TOPs(Teraoperationspersecond)的算力对应的实际每秒计算多少帧数据(例如图片或者视频),以及算法从训练到部署的转换中对精度的保持成为关键。每秒计算多少帧数据的能力,决定了应用和系统厂商能以什么样的性价比来部署AI算法;算法从训练到部署的数据类型转换带来精度损失,决定了应用和系统厂商算法部署前的数据投入(比如如何增加数据来尽量覆盖数据类型转换所带来的损失从而保持精度)、和部署后的实际效果。
肇观电子作为2016年成立的AI芯片领域第一梯队企业,其团队在芯片、数学、算法等方面深耕多年,一直潜心研发核心技术,已获60余件国内外专利授权。
02.AI芯片性能,“又快又准”是主要指标
AI应用和系统的客户对于AI芯片实际的深度神经网络处理能力有着明确需求。对于系统性能而言,“又快又准“是其主要指标。“快”主要取决于芯片的每秒计算能力。芯片是个复杂系统,由于各种因素,芯片的理论计算能力和实际能达到的计算能力之间往往存在差距。 如何能够在单位成本和单位功耗下最优地支持神经网络模型的各种神经层的不同数据类型并使得客户的模型部署的精度损失最小,体现出不同公司之间的技术水平的差异。综合来看,客户可感知、利用、发挥的芯片性能是整个系统的性能的关键因素。
根据不同算法网络的测试结果,N161芯片每TOPS算力下每秒可推理图片的数量展示出了业界领先的水平。同时,N161还支持FP16高精度网络,同样展示出强悍的性能。
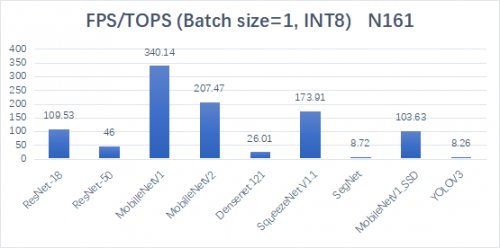
在INT8精度下,N161跑各项网络可以达到的每秒帧数
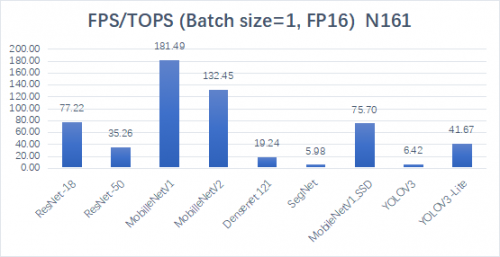
在FP16的精度下,N161跑各项网络可以达到的每秒帧数
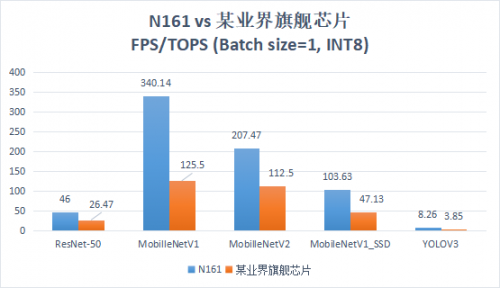
针对五种算法网络,N161芯片与某业界旗舰芯片的运行结果对比
“准”主要取决于芯片对于算法中的神经网络模型的各种神经层的不同数据类型的支持,支持能力方面的差异带来模型部署的精度损失方面的差异。客户的算法从模型的训练到模型的部署的数据类型转换所导致的精度损失往往十分昂贵。比如在无人零售设备的应用中,如果物体识别算法在实际运行中有1%的精度下降,会直接导致货损率的上升以及运营成本的增加。
根据各种不同网络的测试结果,N161 INT8量化网络几乎无精度损失(1%以内)。
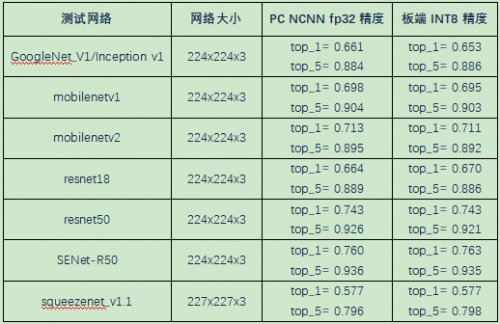
采用1000张imagenet数据测试
基于对应用的深刻理解和长时间的技术积累,肇观电子创新的CVKIT™ NN IP在诸多方面遥遥领先,并已部署至N1系列芯片,以及D163(3D视觉)、V163(车载)芯片。
03.InferStudio™解决“算法落地难”问题
人工智能落地的挑战,一方面在于整个产业链亟待在性能、成本、功耗等方面合用的上游核心芯片来破局;另一方面在于算法部署实施至具体应用所需知识技能过于专业而导致的综合成本高昂。人工智能等相关领域的人才,由于稀缺,其薪酬水平较高已是业界共识;既懂AI算法又懂硬件部署的人才更为缺乏,这导致很多应用和系统厂商的开发能力较为欠缺,落地较慢。不仅是各个中小企业面对这一挑战,大厂也往往面对高薪招不到合用的人才的问题。人工智能落地成本高昂,是业界公认的一个突出问题。
为了解决“算法落地难”的问题,肇观电子发布了“5分钟部署”的AI应用开发平台Infer Studio™,助力算法快速商用。InferStudio™能够将算法“翻译”成芯片能读懂的表述文件,并快速部署,这种“一键式”开发体验显著地提高了开发者的效率。Infer Studio™支持TensorFlow / TensorFlow Lite / ONNX / Caffe这些主流框架,开发者可以自由选择训练框架。从功能上来说,在软件层Infer Studio™ 具有 Model Visualization 可视化模型、Compiler 编译器、Evaluator 效果评估器、Debugger 调试器四种功能。

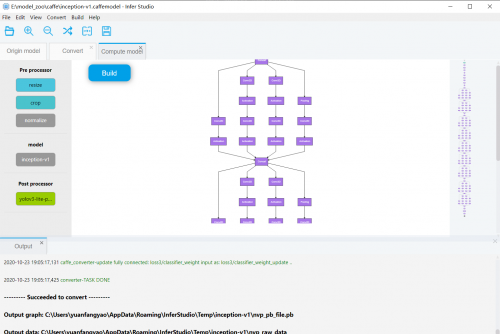
InferStudio™ 操作平台
不同于算法表现出来的精彩效果,算法网络在PC端呈现出来的是一连串晦涩难懂的二进制数据和无数层的文本描述。然而Model Visualization可视化模型却可以将这些描述转换成网络图,便于开发者直观地分析网络的结构和属性。
Compiler编译器可支持将客户基于主流AI框架开发出来的算法,包括Caffe,Tensorflow,Tensoflow Lite,ONNX等,转换成芯片可以理解的表述文件。同时Compiler还能完成Weight Compression的功能,进一步精简算法模型大小,使其真正部署到存储空间有限的端设备,提升了网络推理性能。同时,编译器也支持算子融合,预编译等优化选项,进一步将推理性能提升至硬件的极限
一套在PC端运行强大的算法如何确保在芯片上也能快速呈现效果?Evaluator评估器可以帮助客户快速评估结果是否正确,性能是否能被发挥出来。通过Infer Studio™的Evaluator功能,客户可以一键式将模型部署在设备上,全面透彻的看到运行结果,同时对分类,检测分割等网络在测试图片中可视化呈现算法效果。
为了高效分析算法移植过程中可能遇到的偏差和兼容性问题,Infer Studio™ 的Debugger调试器能够按层调试,随时发现错误。客户可以导出算法运行中的每一层数据,跟原本算法中的每一层数据做对比,便于随时调试,找出错误。
04.InferStudio™ 的行业落地应用
客户的方案在算法移植验证以后,是否也能在产品层面快速部署,正常运行?与Infer Studio™ 配套的SDK可以通过积木搭建的方式快速构建多媒体pipeline,并将算法模型灵活嵌入到pipeline中。
例如,一个经典的AI应用是:VI (Video Input) 从摄像头外部接入原始数据,这些数据经过ISP模块转换成YUV格式,一路传输到Encoder进行编码,并输出。另一路ISP输出的数据传输到CNN引擎运行各种AI算法。AI应用中各个功能模块之间有着灵活的数据流向构建方式;通过模块间Bind(一种数据建立的方法)的方式,客户可以更灵活的根据自己的应用需求,组合功能模块,完成应用部署落地。
客户也可以自由删除某些模块,替换或者增加某些算法模块。所有这些pipeline搭建工作都可以通过可视化或者几行配置代码来实现。将AI算法开发到产品落地的时间压缩到极限。对于典型的AI应用,物体分类,人脸/车辆检测,物体分割等应用,从算法编译到应用部署,5分钟内即可完成。
目前,Infer Studio™ 在诸多客户的项目中作为日常使用的重要工具,得到了普遍认可和好评。
例如:在一个监测司机是否在说话、瞌睡、打电话的车载项目中,工程师需要检测眼部的状态来判断司机是否在走神或者瞌睡,检测耳朵旁边是否有电话,等等。客户原本需要一个星期甚至更久才能让这套算法在芯片上跑起来,但是结合了Infer Studio™之后, 对多个神经网络进行硬件加速,对神经网络的前后处理再结合计算机视觉加速单元 CV Accelerator里的内置算子来完成,使得该算法迅速完成编译并在平台上高性能跑起来。
肇观电子的Infer Studio™是目前市面上罕见的的人工智能算法的硬件移植和部署开发平台,在提高人工智能算法的落地效率、降低部署实施成本方面实效显著,受到下游厂商的广泛好评。
05.结语
人工智能技术所赋予时代的意义,往往短期被高估,长期被低估。作为AI芯片设计领域的核心公司之一的肇观电子,不仅在芯片核心技术上不断突破,还为客户提供 “一键式” 配套开发工具。 这不仅促进了客户的解决方案在应用场景中的部署,也推动了整个人工智能行业的发展。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















