
近日,平安科技联邦学习技术团队的论文《Empirical Studies of Institutional Federated Learning For Natural Language Processing》(联邦学习框架中自然语言处理模型的实证研究)被自然语言处理(NLP)方向的国际学术会议EMNLP 2020收录。
一年一度的全球学术大会EMNLP是计算机语言学和自然语言处理领域最受关注的国际学术会议之一,由国际语言学会(ACL)旗下SIGDAT组织。其中,会议涵盖的语义理解、文本理解、信息提取、信息检索和机器翻译等多项技术主题,是当今学术界和工业界备受关注的热点方向。EMNLP 2020一共收到投稿3114篇,其中录用754篇,录用率不到25%。在即将召开的EMNLP学术会议,来自全球的杰出学者及研究人员将共聚一堂,展示自然语言处理领域的前沿研究成果。这些成果,将代表着相关领域和技术细分中的研究水平以及未来发展方向。
平安联邦学习技术团队近来已发布多项颇具显示度和开创性的科研成果,而这篇论文也是业界发表的在联邦学习框架下实现NLP模型训练的创新性研究成果,是继联邦学习团队在咳嗽检测COVID-19智能系统、Occam自动化机器学习平台研发后获得的又一个创新性的突破,再一次得到了全球专家的认可,同时也成功部署到蜂巢联邦智能平台计算引擎中,该项成果代表着团队在联邦学习和自然语言处理结合领域的技术领先地位。
业内联邦学习NLP模型重磅发布
联邦学习为深度学习提供了一种数据可用不可见的训练方式,因而在深度学习领域激起了新的热潮。利用大量的训练样本,深度学习能够学习到几乎任意任务的数学模型。然而,由于用户隐私政策、数据监管法规的限制,很多数据碎片化地保存在不同机构的数据库里,传统的深度学习方法将无法在这样的数据上进行训练,联邦学习正是为了解决这样的数据孤岛问题应运而生。
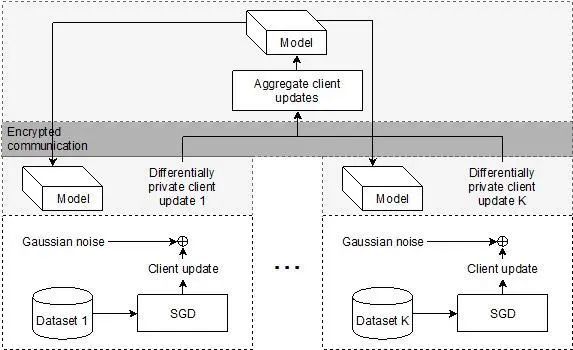
图1 差分隐私保护的联邦学习系统架构图
(图中不同灰度的背景颜色代表着不同的安全保护边界)
随着新的训练方法和计算硬件的发展,联邦学习被越来越多地应用到图像、语音、文本等多种数据的任务训练中。在论文中,团队在支持GPU的服务器群集上成功部署了联邦自然语言处理网络。以一个常用的NLP模型:TextCNN为例,展示了联邦学习在自然语言处理领域的应用潜力。此外,团队在联邦网络训练过程中引入了可管理的差分隐私技术,有效保护了联邦学习参与者的数据安全(见图1)。与现有的客户端级别的隐私保护方案不同,团队提出的差分隐私是定义在数据集样本级别的,这与目标场景——机构间的联邦合作训练是一致的。通过综合大量实验分析,团队研究了联邦学习框架下TextCNN模型的超参数的最佳设置并评估了在不均衡数据负载情况下,差分隐私要求对联邦TextCNN模型的性能影响。
实验表明,在联邦模型训练过程中,本地训练使用的采样率对FL模型的性能有很大的影响,可能导致测试精度下降达38.4%。
另一方面,联邦学习对差分隐私使用的不同的噪声乘数级别具有较强的鲁棒性,在一系列不同噪声级别的实验中,测试精度的变化小于3% (见图2)。然而,联邦训练对客户端数据集之间的数据负载均衡性比较敏感。当数据负载不均衡时,模型性能最多下降了10%。这些重要的实验数据展示出,在联邦学习系统中部署一个实际可用的具有差分隐私保护的自然语言处理深度模型的可行性,并揭示了在不同程度的差分隐私保护要求下对系统参数的调整策略,为模型的实际部署提供了可靠的数据支撑。
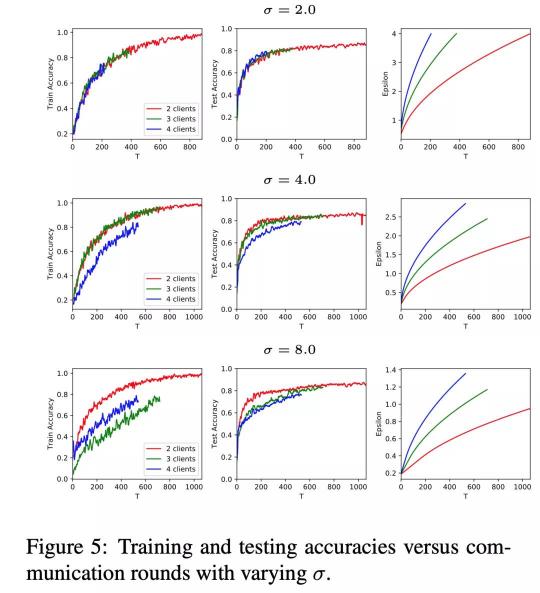
图2 实验结果图
(在不同的差分隐私保护程度σ设置下,联邦TextCNN模型的训练和测试精度变化记录。在σ限制不同时,固定相同的batch size,对应不同的client数据集大小可能导致训练迭代次数的限制,因此部分训练曲线在未完全收敛时被迫中止)
蜂巢联邦智能平台
人工智能的发展需要大量数据,而大数据时代下,隐私是最易触犯的红线。如何有效解决当下人工智能领域发展的难题?联邦学习成为当下最热门的技术研究方向之一。在这样的背景下,平安科技联邦学习技术团队自主研发的蜂巢联邦智能平台也成为了解决当下数据难题与隐私保护的一大利器。
图3 蜂巢联邦智能平台示意图
横纵建模,多角度为打破数据孤岛
在实际的数据运用中,即便是同一家公司内的不同子公司或部门,也需要保护数据隐私。以平安集团为例,平安的财险和寿险各自拥有不同维度的用户数据,却很难把数据直接合并在一起来做建模。从“蜂巢”最初的架构设计上,平安科技就考虑到平安集团各个业务线与子公司之间存在数据壁垒的问题。同样的“数据不通”也反应在企业与企业、企业与政府之间,每家机构都有自己的数据,而基于隐私保护等原因,企业或政府数据不能对外进行共享。
平安科技联邦学习技术团队研发的联邦智能平台蜂巢,就是解决企业数据孤岛问题的商用级解决方案。它能够让参与方在不共享原始数据的基础上联合建模,从技术上打破数据孤岛,从而综合化标签数据,丰富用户画像维度,从整体上提升模型的效果,实现 AI 协作。
“蜂巢”下的加密运算,兼顾隐私保护与使用效率
如何在联邦智能平台保护数据隐私?数据加密是联邦学习的一个重要环节。假设用户的一个是数字“12”,经过公钥加密后会变成一个16位的字符串,这是加密最普遍的方式之一。平安科技联邦智能平台蜂巢可以在保护用户隐私的前提下建模,让原始数据不离开用户,建模所交换的是模型的中间参数和梯度,这便能做到最大程度保护用户隐私。同样是数据加密的问题,由于将数据本身复杂化,平台所耗费的计算资源也比原来更大。对此平安科技联邦智能平台蜂巢则采用GPU等异构计算芯片来加速联邦学习的加密和通信过程,从而达到效率升级的效果。
对于用户数据隐私保护,不同行业有着不同的加密要求。在银行领域,银保监会建议对数据进行国密加密,对加密的稳定性、安全性、合规性要求更高。而平安科技是为数不多的支持国密级加密的企业平台。平安科技联邦智能平台蜂巢充分支持了国密SM2、国密SM4以及混淆电路、差分隐私和同态加密等不同的加密方式,以满足企业各个业务场景的不同需求。
联邦学习作为一个重要的新技术方向,未来有着广阔的发展空间,但在实际落地中,在保护数据隐私的前提下进行 AI 协同,无论是底层技术还是整个部署环节,还有大量的挑战需要克服。平安科技联邦智能平台蜂巢,也将不断深耕技术,帮助企业在数据融合及隐私保护上实现进一步突破。同时,自然语言处理是人工智能最受瞩目的发展方向之一,在金融、零售、医疗等领域有着广阔的应用场景,也是智能座席、智能客服的重要技术基础。联邦学习在自然语言处理的初步尝试,展示了未来联邦学习系统在该方向联合多方个人用户数据,突破现有技术瓶颈的潜力。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















