
随着5G、AI、IoT等技术越来越普及,企业数据量增大,新的数据业务层出不穷,企业对数据分析的灵活性、性能、成本要求越来越高,基于传统大数据Hadoop系统搭建的数据分析平台已无法满足企业多方面的要求。
近年来随着云计算技术发展,越来越多企业选择了以数据湖为中心构建大数据处理平台,数据湖最明显的特征就是存储和计算分离,一方面可以使成本下降;另一方面,可以获得更好的系统可扩展性。
采用数据湖架构,随着企业业务增长,可以在一份数据上不断增加新业务,而不是像传统数据平台那样,每拓展一个新业务就要做一次数据拷贝。
每个硬币都有两面,数据湖方案除了低成本、易扩展的优点外,同时也有一些缺点:
1、无事务能力,数据入库难!
传统数据湖依赖云存储,但云存储一般都没有ACID(Atomicity, Consistency, Isolation, Durability)事务能力,导致在此之上构建的Hive表格、Spark表格等不支持基于事务的数据入库,更不用说数据更新了。
这个弊端极大制约了数据湖的使用场景,企业无法将不断变化的数据快速注入到数据湖内。常常需要在业务层做大量预处理后,才能进入数据湖做分析,处理时延往往在一天以上。
2、分析性能依赖于暴力扫描,即费资源又太慢!
传统数据湖存储依赖云存储,极大降低成本,但做数据分析时属于暴力扫描方式,完全依靠云存储自身的吞吐能力,这种方式只适用于ETL、批量计算等对时延不敏感的应用,无法支撑如秒级数据检索、时序数据分析等低时延分析场景。
+ CarbonData,让华为云智能数据湖真正成为企业数据架构的底座
为了解决这些问题,华为云基于云存储+CarbonData构建的新一代数据湖,实现了 “实时数据接入”、“DB数据同步”、“高性能查询和分析”等能力,填补了业界能力空白,使云化数据湖可以真正成为企业数据架构的底座。
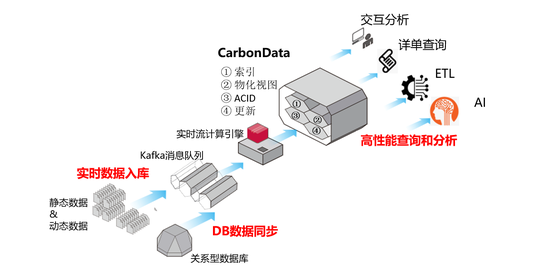
基于CarbonData的华为云数据湖方案如上图描述,Kafka完成数据收集,由Flink、Spark Streaming等流计算引擎完成数据清洗、预处理等业务逻辑,将处理后的数据注入到CarbonData表格中;
继而,用户可使用Spark、Hive、Presto等大数据引擎对CarbonData表格进行交互分析、详单查询和ETL等业务;也可以使用TensorFlow、PyTorch等AI引擎进行AI模型训练、推理等。
下面进一步阐述,加持CarbonData后,华为云智能数据湖的三大特点:
1、实时数据入库
CarbonData增加了对 Flink 的支持,50行代码轻松实现对接 Flink 以CarbonData的格式实现实时数据入库。同时,CarbonData支持ACID事务能力,确保入库操作的原子性和一致性。这使得CarbonData成为唯一一款兼具速度、灵活性和支持 ACID 事务特性的全场景数据湖。
2、DB数据同步
CarbonData支持Delta增量同步,相比Hive使用的数据重写策略,数据同步性能提升10倍。基于CarbonData的数据快速同步能力,企业可以轻松实现关系型数据库到数据湖的数据实时同步,缩短数据入湖可见周期,将数据可见时间从T+1优化为T+0,消除数据入湖壁垒。
3、高性能查询和分析
CarbonData支持对云存储的数据构建索引和物化视图,实现10倍以上的查询性能提升。根据业务需求,用户可选择多种索引和物化视图加速能力,包括主索引、二级索引、时空索引、多值列索引、时间序列Rollup、多表Join预聚合等。
CarbonData在构建这些索引的时候,同样遵循ACID事务性,确保索引构建过程中不会对业务查询造成影响。并可以利用云计算的按需扩展能力,加速索引和物化视图的构建性能。
基于CarbonData最新版本的异步索引构建能力,在数据入库实时性要求较高的业务场景,用户可通过“先入库再建索引”的方式,平衡数据入库延迟和查询性能。实现数据入库后即可被查询,并使用周期任务或等到业务闲时再对数据建立索引,大幅提升查询性能。
典型场景分析
某互联网行业用户使用CarbonData构建全场景数据湖,借助“DB数据同步”、“实时数据入库”和“高性能查询和分析”功能轻松构建PB级别、甚至EB级别大数据处理平台。
对于一个日活千万级别的APP应用来说,平均每天约产生500亿条用户行为数据,一年的数据存储量约10PB。在使用CarbonData之前,该用户曾做过如下性能和成本分析:
1、传统Nosql数据库虽然具有较好的数据索引机制,但是“太贵”:
因为要查询快,用户通常会首先考虑HBase, ElasticSearch等自带索引的NoSQL数据库。
以HBase为例,每PB存储的云硬盘成本为70万/月;单台RegionServer可维护不超过10TB的数据, 每PB的数据存储需100台计算节点来部署RegionServer,每台计算节点500元/月,部署的硬件成本为500*100=5万/月,每PB总成本=75万/月。
2、基于云存储+文件虽然具有较好的成本优势,但是“太慢”:
使用Parquet, ORC等列存,可以将数据存储在对象存储中,成本大大降低,每PB存储的对象存储成本约为8万/月;100台计算节点假设每天开机8小时,计算成本5/3=1.67万/月,每PB总成本约9.67万/月,成本大幅下降。
但是由于无索引,只能通过暴力扫描的方式进行查询和计算,在暴力计算时系统往往受限于对象存储带宽,假设对象存储带宽为20GB/s,对10PB全量数据查询一次通常需要4~5个小时(视业务查询条件而定)。
3、云存储+CarbonData, 实现“又快又便宜”的任性:
CarbonData兼具NoSQL的索引性能优势,和Parquet、ORC等文件存储的成本优势,又快又便宜:
1)利用CarbonData的索引、物化视图、缓存等查询优化技术,查询时间从4个小时下降到30秒内,查询性能提升480倍;
2)支持ACID事务和DB数据同步能力,缩短数据入湖可见周期从T+1到T+0;
3)基于存算分离架构,使用云存储+100计算节点按需启停,每PB总成本约9.67万/月,成本降低近10倍。
展望
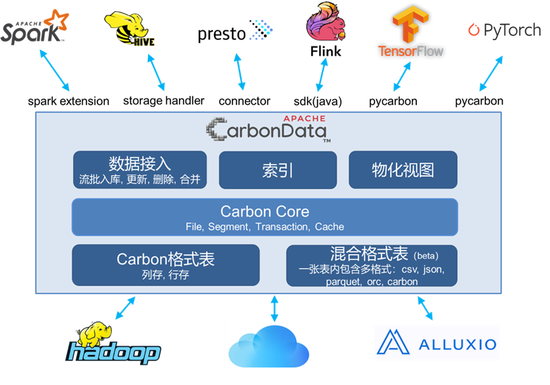
Apache CarbonData是一个高性能EB级别原生Hadoop分析型数据仓库,提供面向对象存储上EB级数据的高性能明细查询能力、交互式查询能力,提供流数据接入、DB数据实时同步和更新能力,提供对主要ETL业务的支持和加速,以及机器学习、深度学习等AI引擎的对接和优化,生态发展越来越完善。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















