
日前,自然语言处理领域国际顶级会议 ACL 2020 (Association for Computational Linguistics)论文接收结果公布。大会共收到 3429 篇投稿论文,投稿数量创下新高。作为计算语言学和自然语言处理领域最重要的顶级国际会议,ACL 录取论文代表了自然语言处理领域在过去一年最新和最高的科技水平以及未来发展潮流。
本届大会,云知声-中科院自动化所“语言与知识计算联合实验室”共有3篇论文被收录,分别在医疗对话的自动信息抽取、国际疾病分类(ICD)自动编码,以及 ICD 自动编码可解释性等领域取得突破。这些最新的自然语言处理算法将为后续研究提供极具价值的经验和方向,已在云知声医疗业务率先应用。
一种面向医学对话的医学信息提取器
MIE: A Medical Information Extractor towards Medical Dialogues
如今,电子病历已经成为现代医疗的重要组成部分,但是目前书写电子病历费时费力,已经成为医生的沉重负担。如果能够从医疗对话中自动地抽取医学信息,将极大缓解医生书写病历的压力。
本文提出一个面向医患对话文本的信息抽取系统,它可以从对话中抽取出症状、检查、手术、一般信息及其相应的状态。这些抽取出的信息将有助于医生书写病历,或者更进一步地应用于病历的自动生成。研究团队收集并标注了1120段在线问诊的医患对话作为数据集,采用滑动窗口形式进行标注,和序列标注相比,减缓了标注难度。在此基础上,针对医疗问诊对话文本的特点和难点,提出一种基于深度匹配的神经网络模型,能够考虑到对话的多轮结构,利用注意力机制捕捉对话中不同轮次之间的交互信息,从而完善医学信息的抽取。

图1:典型的医学对话窗口和相应的带注释的标签
HyperCore:基于双曲空间和共现图表示的ICD自动编码
HyperCore: Hyperbolic and Co-graph Representation for Automatic ICD
Coding
国际疾病分类(International Classification of Dieases,ICD)是由世界卫生组织发起的,针对各种疾病做出的国际通用的统一分类方法,这种方法赋予每种疾病一个独特的编码。ICD 编码的普及和应用能够极大促进世界范围内疾病的信息共享和临床研究,并对健康状况研究、保险索赔、发病率和死亡率统计产生积极的影响。
长期以来,ICD 编码一直由专业编码员人工完成。人工编码耗时费力,而且非常容易出错,同时不断更新 ICD 代码版本会导致代码数量大幅度增加,对编码人员的要求越来越高。数据显示,在美国每年因为编码错误以及用于提升编码质量的相关成本超过250亿美元。
为了缓解人工编码的问题,一些工作开始尝试利用机器自动完成 ICD 编码任务。但是现有的方法独立地预测每个编码,而忽略了编码的两个重要特征——层级性和共现性。
在本文中,研究团队提出了使用双曲空间和共现图卷积神经网络针对性地建模上述两种性质。具体来说,提出了一种双曲线表示方法来利用编码的层次结构。此外,提出了一种共现图卷积网络来利用编码的共现性。在国际公开数据集上的实验取得了最好的效果。
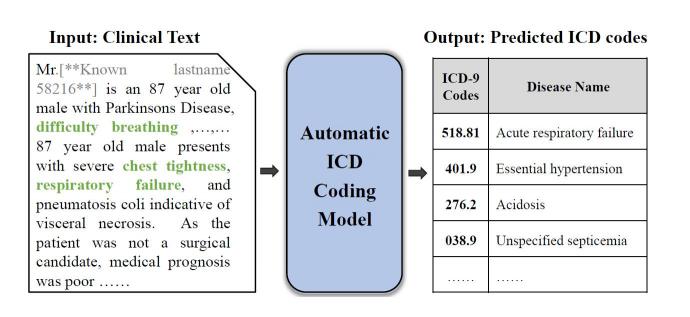
图2:自动ICD编码任务的示例
Clinical-Coder:面向中文临床记录的ICD-10自动编码
Clinical-Coder: Assigning Interpretable ICD-10 Codes to Chinese Clinical Notes
国际疾病分类(ICD)作为世卫组织成员国在卫生统计中共同采用的对疾病进行编码的标准分类方法,是目前国际上通用的疾病分类方法。目前广泛使用的国际疾病分类第十次修订版(简称 ICD-10)的编码数量达到了72,184个,是以前版本(ICD-9)的五倍多。
为了缓解人工编码耗时、费力、容易出错的问题,很多工作开始研究利用机器进行自动的 ICD 编码。这些方法虽然取得了很大的成功,但仍然面临着预测结果可解释性问题的严峻挑战,可解释的结果对临床医学决策具有重要意义。
针对此问题,并结合中文的语言特点,研究团队提出了一种基于空洞卷积和N-gram语言模型的ICD自动编码方法,利用空洞卷积捕获非严格匹配的语义片段证据,利用 N-gram 捕获严格匹配的语义片段证据,进而二者联合使用,共同提升预测结果的可解释性。实验结果显示,该方法不仅能在中文数据集上取得显著的效果,在国际公开的英文数据集上也有不错的效果。

图3:两种语义片段证据类型-非严格匹配和严格匹配
值得一提的是,在医疗领域,云知声-中科院自动化所语言与知识计算联合实验室基于自然语言处理技术构建的医疗知识图谱已储备约 50万医学概念,超过 169 万医学术语库和 398 万医学关系库,涵盖了绝大部分药品、疾病、科室与检查,规模达国际领先水准,并在语音病历,病历生成、病历质控、辅助诊断系统等具体应用中发挥了重要支撑作用。
关于 ACL :ACL 是自然语言处理领域顶级国际学术会议,由计算语言学学会(Association for Computational Linguistics)主办,每年举办一次。其接收的论文覆盖了语言模型、句法分析、语义分析、篇章分析等计算语言学基础研究以及信息抽取、问答系统、对话生成、机器翻译、自动文摘、情感分析、社会计算等自然语言处理应用研究等众多方向。第 58 届 ACL 年会 ACL 2020 原定于 7 月 5 日-10 日在美国华盛顿西雅图举行,因疫情影响今年将改为在线会议。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















