
一、云狐简介
云狐语音识别软件是基于百度智能云,由进击的狐狸进行开发的一款软件。注意,因为核心类代码是2017年就已经写好的了,所以使用的C#SDK包不是最新的。云狐目前支持的平台是Windows系统平台,使用时需要安装微软最新的.netframework。云狐的主要功能是长时间的语音识别,支持时长超过一分钟的各种类型的语音文件识别,缺点就是速度较慢一些。
另外,云狐和云猫实际上是姐妹软件,因为他们都是基于百度智能云,用C#进行开发的,使用的是百度最新的人工智能技术。而且他们目前都是免费的。这里联动一下,对云猫OCR和云狐语音感兴趣的同学,可以百度搜索“云猫OCR”或“云狐语音”进行了解。
二、云狐的简单评测
云狐软件自带有计时功能,我们可以简单做一下评测。从上文视频演示的结果可以看出,1分钟左右的语音文件,云狐可以在10秒以内识别完毕,而30分钟左右的语音文件,云狐需要120秒即2分钟左右,才能识别完毕。从中推算出识别速度大概是4秒/分钟。
三、云狐软件的代码原理
百度智能云给出的长语音识别接口只支持一分钟以内的语音文件的识别。而对于超过一分钟的语音文件识别,我们需要怎么做呢?
云狐软件的原理就是:把超过一分钟的文件进行切片,切成若干个小于或者等于一分钟时长的语音文件。对每个切片文件调用百度云语音识别接口进行识别,再把结果串联起来即可。
四、云狐的代码简明解析
(一)核心类foxSpeechDemo

上面的代码是根据百度SDK包文档,进行少量改动实现的。注意为了简便,这里贴出的代码段可能跟具体的云狐实现代码有一些出入。
不是任何一个语音文件都可以交给百度智能云直接识别。文件需要预处理,不然识别效果会很差。具体来说,作者用FFmpeg对语音文件进行预处理,然后再用百度接口识别。FFmpeg的命令行预处理类似下面的形式:
ffmpeg-y-i003_16k.wav-acodecpcm_s16le-fs16le-ac1-ar1600016k.pcm
(二)预处理的辅助函数
共有大概4个关于预处理的辅助函数,代码如下:
1.此函数的主要功能是用C#程序自动执行命令行语句,它可执行任何语句的命令行,stringcmdStr是形参,可以将命令行语句赋值给cmdStr进行执行。


2.此函数表示利用ffprobe命令行获取语音文件的时长信息,以便对语音文件进行分割,注意返回值是整形变量。比如语音时长有1.5分钟,这个函数就会返回2,以此类推。

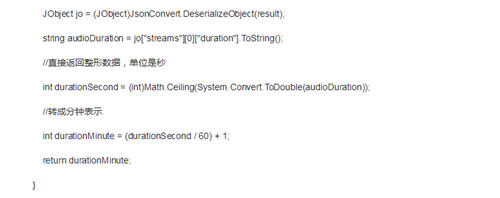
3.此函数主要功能是对语音文件进行分割,时间单位是秒。比如我有一个2分钟的语音文件,程序就把这个文件分成2块,每块60秒即1分钟,以此类推。

4.此函数的主要功能是把切片文件转换成百度云能够进行正常识别的文件格式。

(三)主函数的代码逻辑


上面是主函数里面的核心代码段,里面有很多的注释,大家可以仔细看看。主要功能就是整合预处理辅助函数的作用,把文件切片并转换格式,最后提交给百度智能云进行识别,并对识别结果进行解析,把json转换成对人类友好的文本格式。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















