
近日,腾讯多媒体实验室设计的基于深度学习的全参考视频质量评估算法DVQA在Github上正式开源,该算法模型的性能目前在公开测试数据集上取得业界领先成绩。
开源地址:https://github.com/Tencent/DVQA
国内镜像地址:
https://git.code.tencent.com/Tencent_Open_Source/DVQA
(登录后才能访问公开项目)
腾讯工蜂源码系统为开源开发者提供完整、最新的腾讯开源项目国内镜像
视听时代,音视频应用越来越广泛:直播、短视频、视频节目、音视频通话……近期由于新冠疫情带来的在线协同办公、在线教育类产品的崛起,更带来了线上音视频需求的爆发,用户对音视频质量诉求也愈加强烈。
在整个视频链路中,大部分模块都可以精确度量,如采集、上传、预处理、转码、分发等。然而未知的部分却恰恰是最关键的部分,即用户的视频观看体验到底怎么样。目前行业内的视频质量评估方法分为两大类:客观质量评估与主观质量评估。前者计算视频的质量分数,又根据是否使用高清视频做参考、源视频是专业视频还是用户原创视频等进一步细分;后者主要依赖人眼观看并打分,能够直观反映观众对视频质量的感受。然而,这些方法仍存在耗时费力、成本较高、主观观感存在偏差等难题。
多媒体实验室提出的视频质量评估解决方案,首先结合业务需求,使用“在线主观质量评测平台”,来构建大规模主观质量数据库,同时使用所收集的主观数据来训练基于深度学习的客观质量评估算法,最后把训练好的质量评估算法部署到业务线中,闭环监控可能存在的质量问题。从以上三个角度出发,DVQA能够在兼顾不同业务、场景的前提下,满足效率与精度两大需求。
DVQA包含多个质量评估算法模型,本次开源的是针对PGC视频的算法C3DVQA。本项目使用Python开发,深度学习模块使用PyTorch。代码使用模块化设计,方便集成较新的深度学习技术,灵活的自定义模型,训练和测试新的数据集。
在算法设计上,C3DVQA所使用的网络结构如下图所示。其输入为损伤视频和残差视频。网络包含两层二维卷积来逐帧提取空域特征。级联后使用四层三维卷积层来学习时空联合特征。三维卷积输出描述了视频的时空掩盖效应,再使用它来模拟人眼对视频残差的感知情况:掩盖效应弱的地方,残差更容易被感知;掩盖效应强的地方,复杂的背景更能掩盖画面失真。
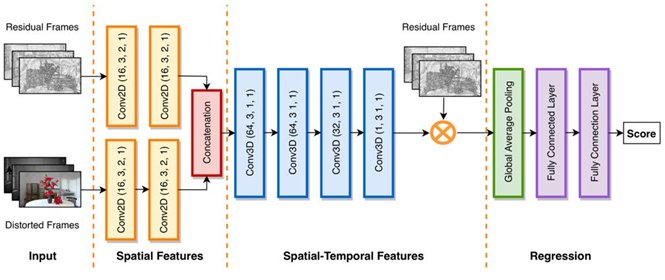
网络最后是池化层和全连接层。池化层的输入为残差帧经掩盖效应处理后的结果,它代表了人眼可感知残差。全连接层学习整体感知质量和目标质量分数区间的非线性回归关系。
在评测结果上,腾讯多媒体实验室在LIVE和CSIQ两个视频质量数据集上对所提出算法的性能进行验证。并使用标准的PLCC和SROCC作为质量准则来比较不同算法的性能。将所提出的C3DVQA与常用的全参考质量评估算法进行对比,包括PSNR,MOVIE,ST-MAD,VMAF和DeepVQA,结果如下表所示。

(LIVE和CSIQ两个数据库上不同全参考算法性能比较)
目前该评估算法已在腾讯内外部多款产品中进行使用验证,如腾讯会议就借助实验室上百个符合ITU/3GPP/AVS等国外内标准的指标进行评判,闭环监控全网的用户体验质量,从用户真实体验出发,不断优化产品性能。
作为最早布局音视频领域的公司之一,从最早的QQ平台,腾讯就试图解决在当年网络条件下若干的音视频通信问题。伴随着5G、云计算、大数据、人工智能技术的发展,腾讯多媒体实验室基于多年的技术沉淀和行业经验,逐步打磨出一条完善且高质量的音视频技术链条。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















