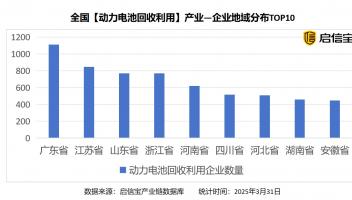
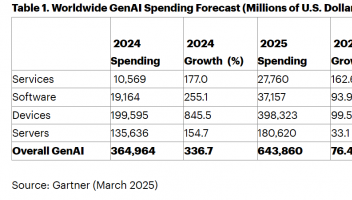
就多任务处理、多语言识别等问题,苹果在论文中给出了自己不同的想法。
最近,苹果发布了一系列论文来阐释语音助手的重要工作机理,公开揭秘Siri,向业界贡献了自己在设计上的不同想法。
在第一篇论文中,苹果就语音助手中的多任务处理问题进行了阐释,它指出在Siri中,唤醒处理通常需要两个步骤:AI首先必须确定输入音频中的语音内容是否与触发短语的语音内容匹配(语音触发检测),然后必须确定说话者的语音是否与一个或多个注册用户的语音相匹配(说话者验证)。一般方法是将两项任务分别来处理,苹果则认为可以用一个神经网络模型同时解决两项任务,同时它表示,经过验证,该方法各方面性能可以达到预期。
在该论文中,研究人员给出了模型示例。他们在包含16000小时带注释样本的数据集中训练了基于两种思路下设计的模型,其中5000小时的音频带有语音标签,其余均只有扬声器标签。相比于一般训练模型去获取多个标签的思路,苹果通过将不同任务的训练数据进行级联来训练多个相关任务的模型。结果发现,在性能表现相同的情况下,苹果新提出的模型反而更适合应用,它能够在两个任务之间共享计算,大大节省了设备上的内存空间,同时计算时间或等待时间以及所消耗的电量/电池数量都将降低。
在另一篇论文中,苹果还介绍了多语言演讲场景的演讲者识别系统设计——知识图谱辅助听写系统决策。以声学子模型为例,它可以基于语音信号传输痕迹来进行预测,并且其上下文感知的预测组件考虑了各种交互上下文信号,其中上下文信号包含有关发出命令的条件信息、已安装的命令语言环境、当前选择的命令语言环境以及用户在发出请求之前是否切换命令语言环境的信息。
结果显示,这一设计的优势在于,它们可以在语音信号太短而无法通过声学模型产生可靠预测的情况下提供帮助。
此外,苹果还提出了一项补充研究,缓解错误触发问题,即忽略不适合语音助手(Siri)的语音。基于图结构设计AI模型的思路,研究人员提出了一种图神经网络(GNN),其中每个节点都与标签相连。结果显示,该模型减少了87%的错误触发。
作者:Lynn
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )