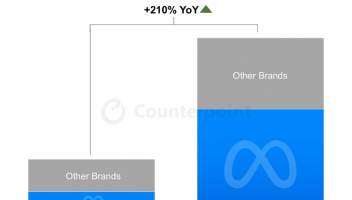
AI 技术在理解层和决策层中赋能自动驾驶
自动驾驶是一种类人驾驶,即计算机模拟人类的驾驶行为,其功能的实现同样分为感知、理解、决策和执行四个层次,由各类传感器、ECU和执行器来实现。
在整个自动驾驶实现的流程中,1)感知层主要依赖激光雷达和摄像头等传感器设备所采集的信息感知汽车周围环境,以硬件设备的精确度、可靠性为主要的衡量标准。2)执行层通过汽车执行器,包括油门、转向和制动(刹车)等,实现车辆决策层输出的加速、转向和制动等决策,主要依靠机械技术实现。3)AI技术主要应用于理解层和决策层,担任驾驶汽车“大脑”的角色。
理解层对感知层数据进行解析,AI 算法技术优势尽现
依据感知层传感器的不同,理解层主要完成两个任务:车辆的高精度定位,以及物体识别和追踪。
高精度定位任务的实现主要是通过GPS或视觉的算法实现非常精准的车辆定位,目前主要的技术路线有三种:惯性传感器(IMU)和GPS定位、基于视觉里程计算法定位、基于雷达的定位。
AI 算法在理解层最主要的应用是物体的识别和追踪。物体跟踪和识别包括静态物体识别和动态物体识别,对于动态物体还需要对其轨迹进行追踪,基于追踪的结果预测其下一步的位臵,计算出安全的行车空间。自动驾驶车辆需要实时进行多个物体的识别和追踪,典型的物体包括车辆、行人、自行车等。
激光雷达和计算机视觉是实现物体识别/跟踪的两种途径,Google 和Tesla分别代表了这两种不同的技术路线。
激光雷达生成的点云数据包含物体的3D 轮廓信息,同时通过强度扫描成像获取物体的反射率,因此可以轻易分辨出草地,树木,建筑物,路灯,混凝土,车辆等。识别软件算法简单,很容易达到实时性的要求。
计算机视觉的方法是利用深度学习对摄像头图像进行处理,从像素层面的颜色、偏移和距离信息提取物体层面的空间位臵(立体视觉法)和运动轨迹(光流法)。基于视觉的物体识别和跟踪是当前的研究热点,但是总体来说输出一般是有噪音,如物体的识别有可能不稳定,可能有短暂误识别等。
决策层如何应对复杂情形是自动驾驶的关键瓶颈
在理解层的基础上,决策层解决的问题是如何控制汽车行为以达到驾驶目标。在一个具有障碍物并且动态变化的环境中,按照一定的评价条件寻找一条从起始状态到目标状态的无碰撞路径。自动驾驶汽车的决策包括全局性导航规划、驾驶行为决策和运动轨迹规划。1)全局导航规划在已知电子地图、路网以及宏观交通信息等先验信息下,根据某优化目标,选择不同的道路。2)驾驶行为决策根据当前交通状况、交通法规、结构化道路约束,决定车辆的目标位臵,抽象化为不同的驾驶行为,如变换车道、路口转向等。3)运动轨迹规划是基于驾驶行为决策,躲避障碍物,对到达目标位臵的路线进行规划。
基于规则的传统算法,在应对复杂情形下的决策仍存在挑战。道路上的交通参与者(车辆、行人、自行车等)的状态和意图具有不确定性,决策算法需要在这样的环境下,以较短的时间进行行为决策,无疑是个技术难点。当前自动驾驶的决策算法多基于规则,如有限状态机算法、决策树等算法等。需要开发者利用专业知识对特定问题进行抽象和建模,实际上这种方式缺乏灵活性,特别是在复杂情形下,交通参与者的不确定性更高,算法更是难以做到面面俱到。
强化学习在自动驾驶决策层具有应用前景。强化学习的目的是通过和环境交互学习到如何在相应的观测中采取最优行为。行为的好坏可以通过环境给的奖励来确定。不同的环境有不同的观测和奖励。例如,驾驶中环境观测是摄像头和激光雷达采集到的周围环境的图像和点云,以及其他的传感器的输出。驾驶中的环境的奖励根据任务的不同,可以通过到达终点的速度、舒适度和安全性等指标确定。当前增强学习的算法在自动驾驶汽车决策上的研究还比较初步,有试错次数多、算法可解释性差等弱点。
深度学习算法在自动驾驶中广泛应用,端到端自动驾驶仍具挑战
车辆的道路行驶环境非常复杂,需要处理大量非结构化数据。深度学习算法能够高效的处理非结构化数据,并自动地从训练样本中学习特征,当训练样本足够大时,算法能够处理遇到的新的状况以应对复杂决策问题。以基本的车辆识别问题为例,在用足够多的汽车图像对算法进行训练后,算法具备了识别汽车的能力。
深度学习在自动驾驶中的应用可以分为两个学派:端到端式(End-to-End architecture)和问题拆解式(SemanticAbstraction)。与人类相比,在端到端式的构架中,一个DNN网络模拟了人的整个驾驶行为;而在问题拆解式的构架中,每个DNN网络仅模拟了人的一部分驾驶行为。
端对端式不需要人工将问题进行拆解,只需要一个深度神经网络(DNN),在经过训练后,基于传感器的输入信息(如照片),直接对车辆的加减速和转向等进行控制。
问题拆解式需要人工将问题进行拆解,分别训练多个DNN网络,实现诸如车辆识别、道路识别、交通信号灯识别等功能。然后基于各个DNN网络的输出,再对车辆的加减速和转向进行控制。
目前,问题拆解式深度学习在自动驾驶领域得到广泛的应用,主要是进行图像识别。如识别行驶途中遇到的车辆、行人、地上的交通标志线、交通信号灯等。在KITTI2数据集上,排名第一的车辆识别算法已经能够达到92.65%的准确率3。以色列Mobileye是这个领域的领军人物,其推出的基于摄像头的图像识别解决方案EyeQ得到了业内的认可,被10多家汽车制造商超过100种车型所采用。众多创业公司也试图从这个角度切入自动驾驶领域,提供图像识别算法,如商汤科技、图森互联、地平线科技等。
NVIDIA在测试车上通过端到端式的深度学习实现了对车辆转向的控制,百度在2017年CES上推出了开源的端对端的自动驾驶平台Road Hackers及训练数据。目前端到端方案需要大量的数据进行模型训练(模型参数更多),算法的可解释性变差,难以进行错误排查,在可靠性上也存在一定问题,仍处在较为初级的阶段。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )